在这一篇文章中我先来介绍一下lua解析一个脚本文件时要用到的一些关键的数据结构,为将来的一系列代码分析打下一个良好的基础。在整个过程中,比较重要的几个源码文件分别是:llex.h,lparse.h、lobject.h和lopcode.h。
在llex.h中
1 typedef struct Token {2 int token;3 SemInfo seminfo;4 } Token; Token代表了一个词法单元,其中token表示词法类型如TK_NAME、TK_NUMBER等如果不是这些类型则存放则词素的字符表示,例如分析的代码会这么判断词素单元:
1 switch (ls->t.token) { 2 case '(': { 3 //... 4 } 5 case TK_NAME: { 6 //... 7 } 8 default: { 9 //...10 } 在Token中SemInfo存放了一些语义相关的一些内容信息
1 typedef union {2 lua_Number r;3 TString *ts;4 } SemInfo; /* semantics information */ 其中当token是数字是内容存放在r中,其他情况存放在ts指向的TString中。
下面是最重要的一个数据结构之一
1 typedef struct LexState { 2 int current; /* current character (charint) */ 3 int linenumber; /* input line counter */ 4 int lastline; /* line of last token `consumed' */ 5 Token t; /* current token */ 6 Token lookahead; /* look ahead token */ 7 struct FuncState *fs; /* `FuncState' is private to the parser */ 8 struct lua_State *L; 9 ZIO *z; /* input stream */10 Mbuffer *buff; /* buffer for tokens */11 TString *source; /* current source name */12 char decpoint; /* locale decimal point */13 } LexState; LexState不仅用于保存当前的词法分析状态信息,而且也保存了整个编译系统的全局状态。current指向了当前字符,t存放了当前的toekn,lookahead存放了向前看的token,由此我认为lua应该是ll(1)的~哈哈(不知道对不对)。fs指向了parser当前解析的函数的一些相关的信息,L指向了当前lua_State结构,z指向输入流,buff指向了token buffer,其他的看注释吧。
下面看看lparse.h文件中的重要结构:
1 typedef struct expdesc {2 expkind k;3 union {4 struct { int info, aux; } s;5 lua_Number nval;6 } u;7 int t; /* patch list of `exit when true' */8 int f; /* patch list of `exit when false' */9 } expdesc; expdesc是存放了表达式的相关描述信息,k是表达式的种类,u在不同的表达式中有不同的含义。
1 typedef struct upvaldesc {2 lu_byte k;3 lu_byte info;4 } upvaldesc; upvaldesc是存放了upval的相关描述信息。
最后是本文件中最重要的结构:
1 typedef struct FuncState { 2 Proto *f; /* current function header */ 3 Table *h; /* table to find (and reuse) elements in `k' */ 4 struct FuncState *prev; /* enclosing function */ 5 struct LexState *ls; /* lexical state */ 6 struct lua_State *L; /* copy of the Lua state */ 7 struct BlockCnt *bl; /* chain of current blocks */ 8 int pc; /* next position to code (equivalent to `ncode') */ 9 int lasttarget; /* `pc' of last `jump target' */10 int jpc; /* list of pending jumps to `pc' */11 int freereg; /* first free register */12 int nk; /* number of elements in `k' */13 int np; /* number of elements in `p' */14 short nlocvars; /* number of elements in `locvars' */15 lu_byte nactvar; /* number of active local variables */16 upvaldesc upvalues[LUAI_MAXUPVALUES]; /* upvalues */17 unsigned short actvar[LUAI_MAXVARS]; /* declared-variable stack */18 } FuncState; 在编译过程中,使用FuncState结构体来保存一个函数编译的状态数据。其中,f指向了本函数的协议描述结构体,prev指向了其父函数的FuncState描述,因为在lua中可以在一个函数中定义另一个函数,因此当parse到一个函数的内部函数的定义时会new一个FuncState来描述内部函数,同时开始parse这个内部函数,将这个FuncState的prev指向其外部函数的FuncState,prev变量用来引用外围函数的FuncState,使当前所有没有分析完成的FuncState形成一个栈结构。bl指向当前parse的block,在一个函数中会有很多block代码,lua会将这些同属于同一个函数的block用链表串联起来。jpc是一个OP_JMP指令的链表,因为lua是一遍过的parse,在开始的时候有一些跳转指令不能决定其跳转位置,因此jpc将这些pending jmp指令串联起来,在以后能确定的时候回填,freereg为第一个空闲寄存器的下标,upvalues数组保存了当前函数的所有upvalue,nactvar是当前作用域的局部变量数。
在lparse.c中定义了BlockCnt
1 /* 2 ** nodes for block list (list of active blocks) 3 */ 4 typedef struct BlockCnt { 5 struct BlockCnt *previous; /* chain */ 6 int breaklist; /* list of jumps out of this loop */ 7 lu_byte nactvar; /* # active locals outside the breakable structure */ 8 lu_byte upval; /* true if some variable in the block is an upvalue */ 9 lu_byte isbreakable; /* true if `block' is a loop */10 } BlockCnt; Lua使用BlockCnt来保存一个block的数据。与FuncState的分析方法类似,BlockCnt使用一个previous变量保存外围block的引用,形成一个栈结构。

下面介绍一些在lobject.h文件里面的数据结构
1 /* 2 ** Function Prototypes 3 */ 4 typedef struct Proto { 5 CommonHeader; 6 TValue *k; /* constants used by the function */ 7 Instruction *code; 8 struct Proto **p; /* functions defined inside the function */ 9 int *lineinfo; /* map from opcodes to source lines */10 struct LocVar *locvars; /* information about local variables */11 TString **upvalues; /* upvalue names */12 TString *source;13 int sizeupvalues;14 int sizek; /* size of `k' */15 int sizecode;16 int sizelineinfo;17 int sizep; /* size of `p' */18 int sizelocvars;19 int linedefined;20 int lastlinedefined;21 GCObject *gclist;22 lu_byte nups; /* number of upvalues */23 lu_byte numparams;24 lu_byte is_vararg;25 lu_byte maxstacksize;26 } Proto; 结构体Proto是lua函数协议的描述,在lua解析脚本时首先会将main chunk代码包裹为一个函数,用main proto描述,接着将里面定义的内部函数一一用Proto结构体描述,将这些Proto的关系用树来组合起来,例如有lua源码文件如下
1 a = 12 function f1()3 -- ...4 end5 function f2()6 function f3()7 -- ...8 end9 end
则parse完成后会有如图如下关系

在Proto结构体中,k指向一个const变量数组,存放则函数要用到的常量;code指向lua parse过程中生成的本函数的instruction集合;p就是指向本函数内部定义的函数的那些proto;locvars指向本函数局部变量数组;upvalues指向本函数upvalue变量数组;nups为upvalue的数量;numparams为函数参数的数量;is_vararg表示函数是否接收可变参数;maxstacksize为函数stack的max大小。
在编译期间lua使用Proto描述函数的,当lua vm开始运行vm时需要根据Proto生成相应的Closure来执行vm instructions。
1 typedef union Closure {2 CClosure c;3 LClosure l;4 } Closure; Closure要么代表了c函数,要么为lua函数,在这里我们只看lua函数的LClosure
1 #define ClosureHeader \2 CommonHeader; lu_byte isC; lu_byte nupvalues; GCObject *gclist; \3 struct Table *env4 //... ...5 typedef struct LClosure {6 ClosureHeader;7 struct Proto *p;8 UpVal *upvals[1];9 } LClosure; 在LClousre中,p就是指向对应函数的Proto结构体啦,upvals顾名思义就是此closure的upvalue数组罗。在ClosureHeader宏中isC表示此closure是否是c函数,nupvalues为upvalue数目,env指向了此closue运行时的函数环境,在lua中可以用stefenv来改变当前函数的环境,就是改变env变量的指向啦。
最后,在文件lopcode.h中定义了lua vm的指令结构
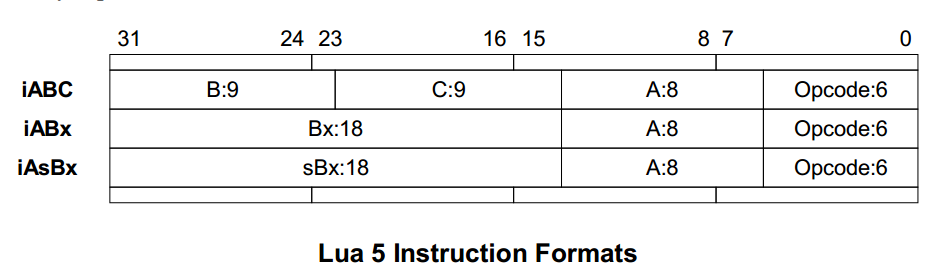
下面是vm指令的一些定义与描述,我在相应vm指令的上方添加了一些注释
1 typedef enum { 2 /*---------------------------------------------------------------------- 3 name args description 4 ------------------------------------------------------------------------*/ 5 OP_MOVE,/* A B R(A) := R(B) */ 6 //Constants are usually numbers or strings. Each function has its own constant list, or pool. 7 OP_LOADK,/* A Bx R(A) := Kst(Bx) */ 8 OP_LOADBOOL,/* A B C R(A) := (Bool)B; if (C) pc++ */ 9 //The optimization rule is a simple one: If no other instructions have been generated, 10 //then a LOADNIL as the first instruction can be optimized away.11 OP_LOADNIL,/* A B R(A) := ... := R(B) := nil */12 13 OP_GETUPVAL,/* A B R(A) := UpValue[B] */14 OP_GETGLOBAL,/* A Bx R(A) := Gbl[Kst(Bx)] */15 OP_GETTABLE,/* A B C R(A) := R(B)[RK(C)] */16 17 OP_SETGLOBAL,/* A Bx Gbl[Kst(Bx)] := R(A) */18 OP_SETUPVAL,/* A B UpValue[B] := R(A) */19 OP_SETTABLE,/* A B C R(A)[RK(B)] := RK(C) */20 21 OP_NEWTABLE,/* A B C R(A) := {} (size = B,C) */22 23 //This instruction is used for object-oriented programming. It is only generated for method calls that use the colon syntax.24 //R(B) is the register holding the reference to the table with the method. 25 OP_SELF,/* A B C R(A+1) := R(B); R(A) := R(B)[RK(C)] */26 27 //The optimization rule is simple: If both terms of a subexpression are numbers, 28 //the subexpression will be evaluated at compile time.29 OP_ADD,/* A B C R(A) := RK(B) + RK(C) */30 OP_SUB,/* A B C R(A) := RK(B) - RK(C) */31 OP_MUL,/* A B C R(A) := RK(B) * RK(C) */32 OP_DIV,/* A B C R(A) := RK(B) / RK(C) */33 OP_MOD,/* A B C R(A) := RK(B) % RK(C) */34 OP_POW,/* A B C R(A) := RK(B) ^ RK(C) */35 OP_UNM,/* A B R(A) := -R(B) */36 OP_NOT,/* A B R(A) := not R(B) */37 //Returns the length of the object in R(B)38 OP_LEN,/* A B R(A) := length of R(B) */39 40 //Performs concatenation of two or more strings.41 //The source registers must be consecutive, and C must always be greater than B. 42 OP_CONCAT,/* A B C R(A) := R(B).. ... ..R(C) */43 44 //if sBx is 0, the VM will proceed to the next instruction45 OP_JMP,/* sBx pc+=sBx */46 47 /*If the boolean result is not A, then skip the next instruction. 48 Conversely, if the boolean result equals A, continue with the next instruction.*/49 OP_EQ,/* A B C if ((RK(B) == RK(C)) ~= A) then pc++ */50 OP_LT,/* A B C if ((RK(B) < RK(C)) ~= A) then pc++ */51 OP_LE,/* A B C if ((RK(B) <= RK(C)) ~= A) then pc++ */52 53 OP_TEST,/* A C if not (R(A) <=> C) then pc++ */ 54 //register R(B) is coerced into a boolean.55 OP_TESTSET,/* A B C if (R(B) <=> C) then R(A) := R(B) else pc++ */ 56 57 //If B is 0, parameters range from R(A+1) to the top of the stack.If B is 1, the function has no parameters.58 //If C is 1, no return results are saved. If C is 0, then multiple return results are saved, depending on the called function59 //CALL always updates the top of stack value.60 OP_CALL,/* A B C R(A), ... ,R(A+C-2) := R(A)(R(A+1), ... ,R(A+B-1)) */61 OP_TAILCALL,/* A B C return R(A)(R(A+1), ... ,R(A+B-1)) */62 //If B is 1, there are no return values. If B is 0, the set of values from R(A) to the top of the stack is returned. 63 OP_RETURN,/* A B return R(A), ... ,R(A+B-2) (see note) */64 65 //FORPREP initializes a numeric for loop, while FORLOOP performs an iteration of a numeric for loop.66 OP_FORLOOP,/* A sBx R(A)+=R(A+2);67 if R(A) =) R(A)*/83 /*Each upvalue corresponds to either a MOVE or a GETUPVAL pseudo-instruction. 84 Only the B field on either of these pseudo-instructions are significant.*/85 //MOVE pseudo-instructions corresponds to local variable R(B) in the current lexical block.86 //GETUPVAL pseudo-instructions corresponds upvalue number B in the current lexical block.87 OP_CLOSURE,/* A Bx R(A) := closure(KPROTO[Bx], R(A), ... ,R(A+n)) */88 89 //If B is 0, VARARG copies as many values as it can based on the number of parameters passed.90 //If a fixed number of values is required, B is a value greater than 1. 91 OP_VARARG/* A B R(A), R(A+1), ..., R(A+B-1) = vararg */92 } OpCode;